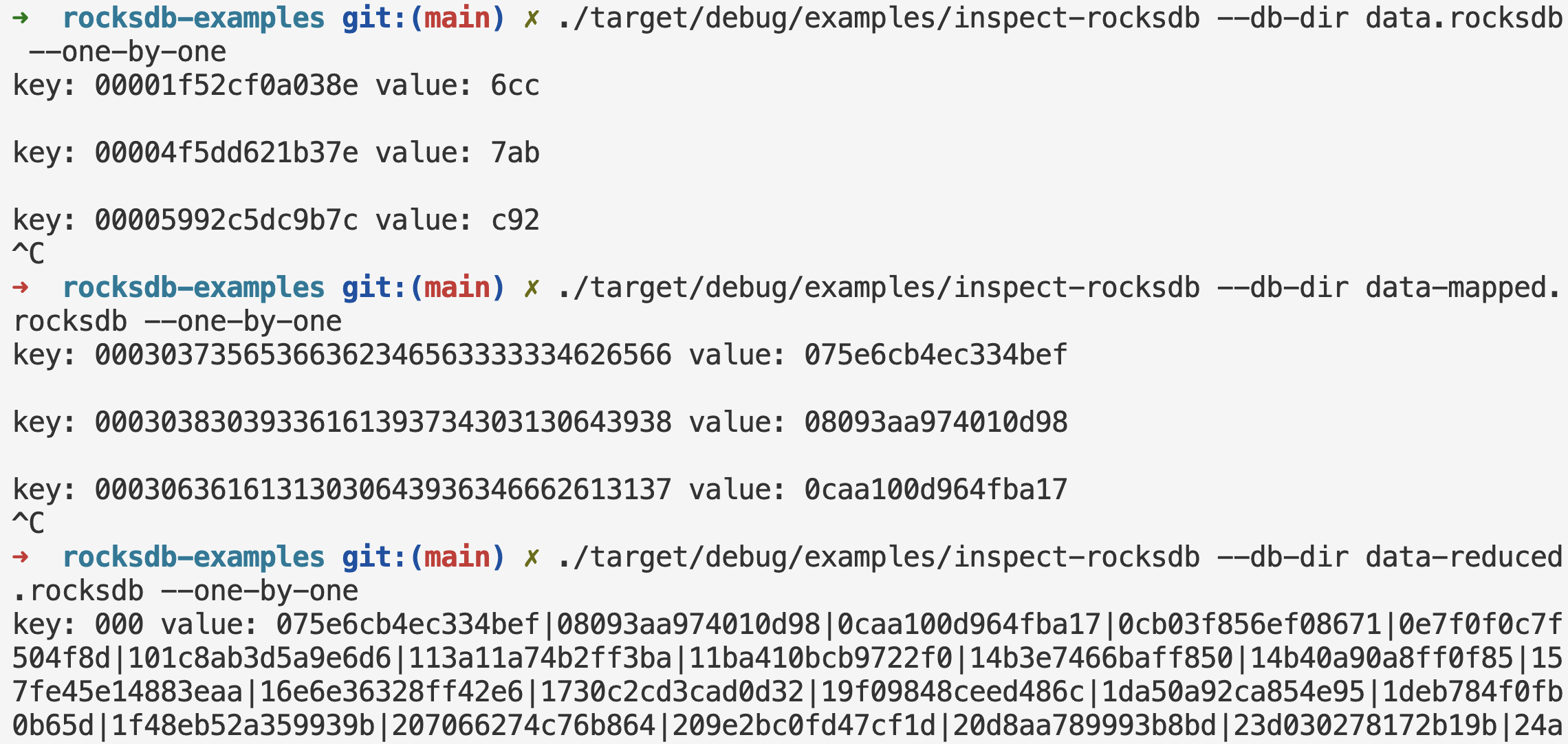
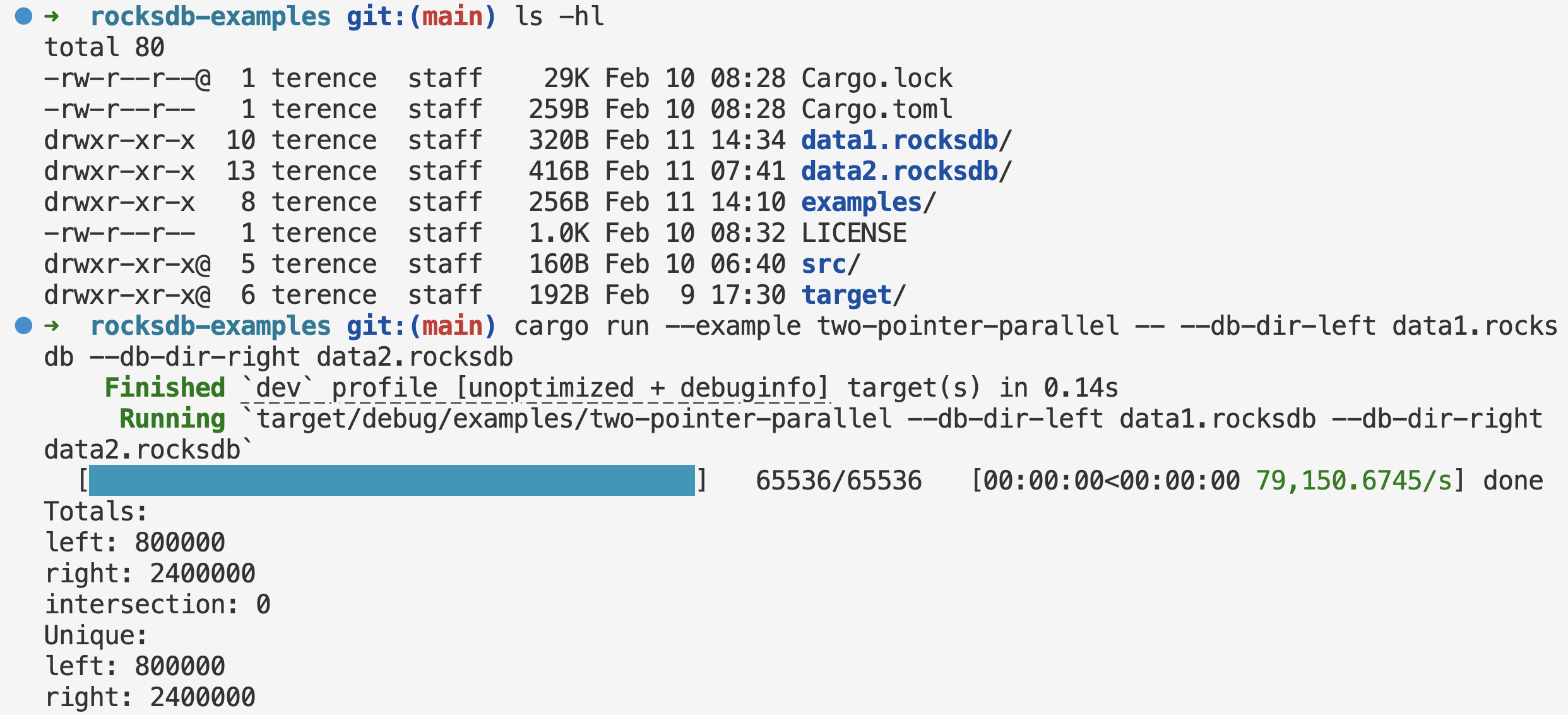
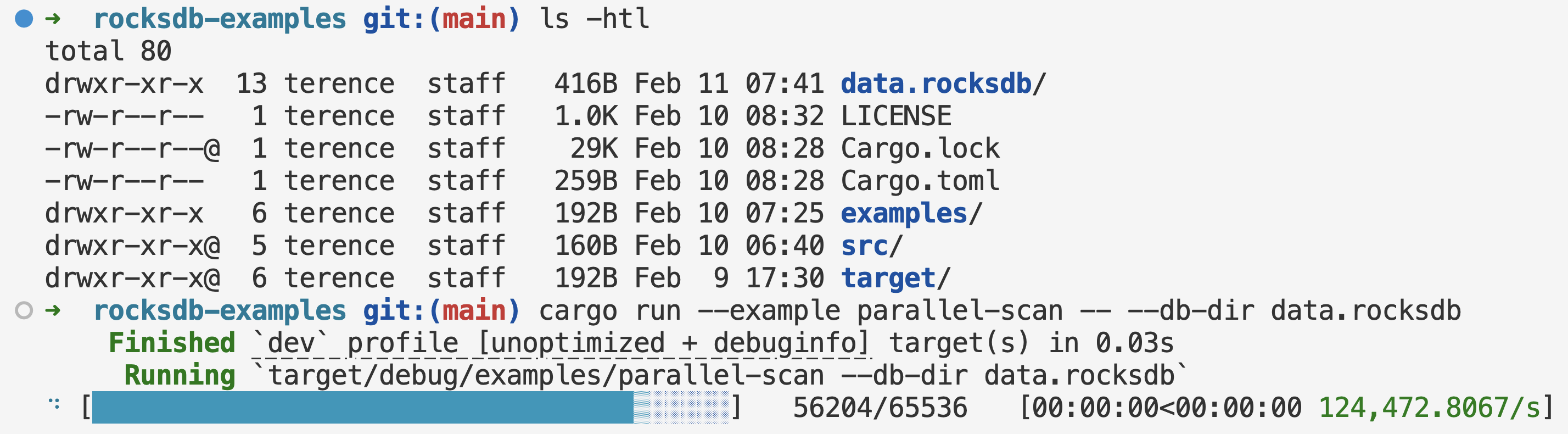
This is the third and final part of the RocksDB in Rust series. In Part I, we looked at how to interact with RocksDB in Rust. In Part II, we looked at how to do parallel two-pointer set operations. In this part, we’ll look at how to do MapReduce for out-of-core aggregations.
Let’s look at the famed algorithm, MapReduce (Wikipedia). MapReduce is a programming model for processing large datasets in parallel originally targeting a big cluster of machines. It is a key component of the Hadoop ecosystem, and is still widely used today. MapReduce is a three-phase process:
Map: The input is split into independent chunks, and each chunk is processed in parallel by a map function.
Shuffle: The output of the map phase is shuffled and sorted by the grouping key.
Reduce: The output of the shuffle phase is aggregated by a reduce function.
From the original paper abstract:
Our implementation of MapReduce runs on a large cluster of commodity machines and is highly scalable: a typical MapReduce computation processes many terabytes of data on thousands of machines.
Back in 2004, TBs of data on HDDs were considered large. In 2026, TBs of data can all fit on one machine with SSDs in RAID0. For example, on AWS EC2, you can get 120TB of NVMe drives on a single i7ie.48xlarge/i8ge.48xlarge instance. We can use one machine to run MapReduce to solve our Big Data problems.
This is the second part of the RocksDB in Rust series. In Part I, we looked at how to interact with RocksDB in Rust. In this part, we’ll look at how to do parallel two-pointer set operations.
How does one get the intersection of two sorted lists in memory?
One could simply convert each list into a hash set to get the intersection. The time complexity is O(n + m) for the conversion, and O(min(n, m)) for the intersection, with n and m being the lengths of the two lists. The hash set lookup is constant. The space complexity is O(n + m) for the conversion.
You could get away with converting only one list, then iterate through the other list to check if the element is in the set. The time complexity is still O(n + m) and the space complexity is O(n). This is how DuckDB and Polars do it. For equi-joins (match by equality), both use the same idea: hash join — build a hash table on one side (usually the smaller), then probe with the other. So it’s the same O(n + m) time complexity and O(n) space complexity, just at columnar scale with SIMD and careful memory layout. When the build side doesn’t fit in memory, DuckDB switches to a partitioned out-of-core hash join (spill to disk, then merge). Polars’ streaming engine processes in batches but does not spill join state to disk — joins can still be memory-heavy or fall back to the in-memory engine, so very large joins may OOM.
Squarely two years ago (Jan 2024), I needed to interact with an in-house K-V store at work, and the underlying DB layer was RocksDB. I had been using and tuning RocksDB in C++ land since 2022 to implement the on-disk Faiss Inverted File index to support our deca-B use case, and spent a good part of 2023 digging my heels into the fast-maturing Rust ecosystem. The natural question was - can I do my data engineering with RocksDB in Rust?
Looking back, I got so much out of that setup, and I still frequently reuse and share with people some of the techniques from that time. This enabled my one-big-machine-style data processing pattern, turning Big Data into smoldata, accelerated by flexibly picking from a fleet of EC2 instances. It’s gotten to a point where a mini blog series is warranted.
Historically, if you want to deal with data in a structured way, you have two more or less isolated options. You either go high-level with packaged database services (OLTP/OLAP, SQL/NoSQL), get locked into their provided transformation functions, and pay the interface overhead. One step down, there are embedded OLTP (SQLite) and OLAP (DuckDB), but they are purpose-built for SQL-centric workloads. On the other end, you roll up your sleeves and reinvent a good part of the wheel from on-disk data representation all the way up. RocksDB filled this gap by providing a strong embedded K-V store for other database services to build upon. But much of the development was confined to the database community, rather than the data engineering community. It was very hard to imagine using systems languages like C/C++ to work on data engineering problems, because one bad pointer may corrupt your data silently, and data outlives software!
Let’s think from first principles. Suppose you have a vision, about a certain shape of a product that is wanted by some people. It involves many functions pushing together to make it into a stable business. The two most fundamental ones are, Product/Engineering that puts in the money to build it, and Sales that gets money from selling it - creating a virtuous loop. Raising money from equity or debt gives the former more lead time, but eventually, the product has to sell. As the business grows, you improve the effectiveness of this loop by adding Customer Success that keeps customers engaged, Marketing that reaches more customers, Legal that protects the business, and Finance that does the accounting, budgeting, and making the business more appealing to investors. There are more support functions like HR, Security, Compliance that may get different emphases in different industries.
Someone needs to be directly responsible for all of the functions. This is the role of the CEO. The CEO and the function heads constitute the executive suite - the first team. All members of the exec suite need to think strategically, and be aligned with maximal information bandwidth. Since they more or less self-organize, my notion of people management isn’t primarily focused on this level.
In this post, I would like to focus more on people management inside of each function, with a particular emphasis on Engineering. Typically, the finer the granularity of responsibilities, the less direct the link between individual performance and overall company success. So the performance evaluation gauges, practices, and culture find other anchors to lean on, e.g. engineering principles, rigor, and teamwork.
turbopuffer is all the rage in vector dbs! In the past, its sizing guide recommended against using turbopuffer if the direct search corpus exceeded a certain number of vectors, likely 1B. In other words, it was built more for multi-tenanted/multi-namespaced hosting use cases, such as its current customers, Cursor, Notion, where each tenant/namespace (end user) would only search a very small portion, filtered down to their own data. Lately, it published an article, explaining searching against a 100B-vector corpus at a whopping 1k qps throughput. There were a lot of admirable first-principles estimates that guided their design choices.
I would like to write down a few observations, wiggle a few parameters, and do some cost analyses.
Vector search is a punishing data access pattern - everything is larger. One field is as big as DIM x DTYPE_SIZE bytes, instead of a single INT64, and the entirety of the field is needed in the query hot path. This makes everything downstream constrained by the sheer data quantity, and bandwidth-bound. Traditional databases put smallish indexes in-mem, and do most of the DB operations on disk. In contrast, vector indexes are big, and often need to reside in DRAM entirely to work properly due to graph-like access patterns. Unless filtered down to a brute-force scannable segment by some natural predicate, it usually means a lot of bandwidth and a lot of compute.
Many people are talking about the power of newer and newer AI agents, and what’s SOTA today is expiring tomorrow. However, many have also observed that AI in automating knowledge work has crossed some sort of boundary of late e.g. Karpathy, Cherny (creator of Claude Code), like the uncanny valley has been crossed. Maybe it was just Opus 4.5, which materially improved beyond the last frontier. Maybe all of those models have improved due to post-training agentic calibration towards practical tasks. From a technological progress standpoint, this may just be one small step towards the eventuality that everyone has been working for years. But it signals some kind of maturation, so it could finally be highly depended upon en masse. Most individuals, and most companies, even the ones actively adopting AI into their people’s daily work lives, have not fully embraced or benefited from this new paradigm. I’m trying to draw some metaphysical points from firsthand.
This post started from researching recent stream processing solutions like RisingWave and Materialize. There are some meta-points worth bringing up, so I’m writing them down.
Why do we need data stream processing in the first place? That’s easy - we need to get a hold of fresh data that keep coming into the system. Fresh data are naturally more interesting to us in many aspects of life. “Fresh” is a moving target in terms of absolute timestamps. However, if we anchor it against “now”, and express it in “past x hours/days”, it is a stable target, only with changing content.
This conceptually makes sense, but why do I need a dedicated stream processing solution? I can simply do on-demand batch queries against my OLAP data warehouse or data lake. They have indexes built on timestamps and other fields, right? This certainly works, and if I don’t do too many such queries, it is a viable approach. After all, the type of data that OLAPs would host tend to be billions of rows, tens of TBs, and keeping them as cold (different S3 tiers) as you can tolerate it is a first-order cost concern. Only start building more indexes and caching data to hotter media like SSDs and RAM if you need more frequent and flexible access. So if you keep making a certain kind of queries, OLAPs may rely on some cache and eviction rules to prioritize them. It’s the system dynamically responding to your user intent.
There are many aspects of AWS EC2 instances. AWS offers a whole fleet of different varieties, targeting a wide range of use cases. It’s a big topic, and one should probably have a conversation with their AI friend and learn as they experiment with a few different scenarios if they want to get a better grounded sense.
Over the years, I have used a few families of instances at length. So here are some of my personal notes.
The t Family
They are burstable instances. The smaller ones are often offered for free as the starter plan for your EC2 journey. You can host bursty web servers on them. I don’t use them as much. They are about 14% cheaper compared to same-gen/spec m instances. e.g. t3.large vs m5.large (both Intel Skylake), and t4g.large vs m6g.large (both AWS Graviton2). The generation numbers are simply zigzagged.
There are a lot of analogies between people in a team setting, and computers. Calling out some of these analogies helps tremendously when it comes to scaling a team.
raw intelligence <> chip processor clock frequency (and turbo when drinking coffee)
learning-based skill-up <> advanced instruction set / specialization
unblocking each other <> embarrassingly parallel patterns / minimizing work in the critical region / indirection / atomicity
work prioritization <> priority queue / nice values
work validation and feedback loops <> compile-time type checking / schema validation / fail-fast design
work planning around existing interfaces/checkpoints & migration <> compiler optimization upholding invariants / pipeline parallelism
Technical leadership - databases, distributed systems, computing fundamentals, Cloud security, scaling and tradeoffs, build vs buy, etc.
Product sense & strategy - how to derive intuition from first-principles thinking & market research, and how to validate ideas before committing the team
Leadership style - org design, leveling, talent retention and hiring, how to drive the team, how to evaluate them and apply productivity pressure
Technical communication - story-telling, simplification of systems, use of analogies
Living the values & principles to build rapport and trust with their first team - increasingly more important as the business grows bigger
can independently take apart an architectural design spec, and independently drive the parts to completion.
clarify logical boundaries, inputs/outputs, and vocalize when unclear or blocked, so that project meets minimal blockage during collaboration.
anticipate, identify bottlenecks during implementation, and find the appropriate algorithmic solutions, to meet latency and throughput requirements.
has enough fundamental working knowledge and experience, and is able to dive into specifics of core technologies in their stack given a reasonable amount of time, and surgically solve the issue according to well established patterns without them reappearing as compounding complexities.
In some ways, it’s easier to check/evaluate a senior person, because there are fewer convergence points that practically every senior person will encounter in their professional lives. For example, a senior systems engineer has to be able to explain and implement a simple hashmap, and explain the various concepts and behaviors. There is no way around it, because without that knowledge, they can’t solve a class of problems.
The other side of the coin is, it’s harder to evaluate a pre-senior person, because it comes a lot down to individual drive and passion. They shine on a team when they are motivated and can do many things to push the projects forward. It’s hard to find those knowledge convergence points to test them during the interviewing process.
Here are some fundamental working knowledge and/or core technologies in different roles.
There aren’t many ways to become better at work as a team. Below is a retrace from personal experience working at different companies and roles, and taking ownership of different projects. I’m writing these down to lay the backdrop as to what a high mark looks like.
Prioritization. Some tasks are more time-sensitive. Some become dependencies of bigger plans. This applies to balancing your own projects & tasks, as well as coordinating with your manager & other teams on the same project. A great outcome is that the most important projects move forward at full speed according to the team plan.
Work through and around blockage by external factors & other team members. Everyone is bound to be blocked by something or someone at times. Don’t just passively wait. Either proactively engage with someone who is blocking you, or vocalize to your manager who can help you get unstuck. Communicate immediately when you realize what you want to do cannot make progress unless something else happens. Your manager can only effectively coordinate something when the thing is communicated. If you have to wait on someone, communicate, and shift gears onto something else in the meantime, be it a backup project, or something exploratory, or technical learning that furthers your skills. Having something as a backup to work on deepens your technical expertise, broadens your scope, and creates more ownership and opportunities to grow. It marks you as exemplary, and the effort will not get overlooked.
Make progress on mastering domain-critical knowledge and skills, and use them at work. It creates a culture of learning, spanning a longer time window, and is the only effective way to work smarter and better. There are some subjects in everyone’s role that once mastered, make the implementations simpler, more scalable, and less maintenance-prone. Identify them and be good at them. Find tasks that allow you to flex those skills on them. This will not go unnoticed.
Note: this doc’s audience is leadership & managers. Managers have an elevated role because they sit at the neck of operations, and if they are not on the same page with leadership on defining the team culture and how it exemplifies itself, the team culture effectively does not exist for people on the ground.
People with the trite gripe of management usually take the frame of “true productivity” vs “hours of work”. But this framing is misguided. Given a comfortable work schedule, putting in the necessary hours is a necessary but not sufficient condition for true productivity. It’s one thing to claim staying the hours does not mean being productive, but it’s quite another thing to claim not having enough time somehow makes one more productive.
Terence shares how Clearview AI’s infra needs evolved and why they chose ScyllaDB after first-principles research. From fast ingestion to production queries, the talk explores their journey with embedded DB readers and the ScyllaDB Rust driver, plus config tips for bulk ingestion and achieving data parity.
I presented at the local MadPy meetup group on the new possibilities in the Python ecosystem in light of recent development in the Rust world. Spent some time curating those links, so they may be worth a shuffle!
In case the embedded slides are not loading, here is the Google Slides.
I wanted to write this post after juggling PBs of (non-tabular) data in the past year at work, and having experienced first-hand how amazing the Big Data landscape is morphing into in the mid-2020s. The ground is shifting under our feet, and individuals & small teams are immensely empowered with recent advances in hardware capabilities, accessible infrastructure, and modern software tooling. I would like to reaffirm that, as data practitioners we totally could, and should do serious work on one single big machine on a good cloud platform, and weigh the pros and cons of adopting abstractions carefully in case of scaling out. We don’t have to be impeded by the idea that Big Data has to be solved by a cluster of machines through distributed computing, thus out of reach for most developers. I will also lay out a minimally viable way to linearly scale out the occasional data processing needs, which can be particularly helpful for non-tabular data, where unified frameworks are still lacking.
Note: The workload described in this post is non-taublar data, usually revolving around big bespoke formats, raw media files, and ML records with binary data and tensors/arrays. Unlike tabular data with tens of popular cluster solutions, working with non-tabular data is more ad hoc. If you work with tabular data, and need to frequently do aggregation or training with columns of data, existing data warehouse and data lake solutions are quite advantageous.
In the past 10 years, a couple of major changes took place in computing:
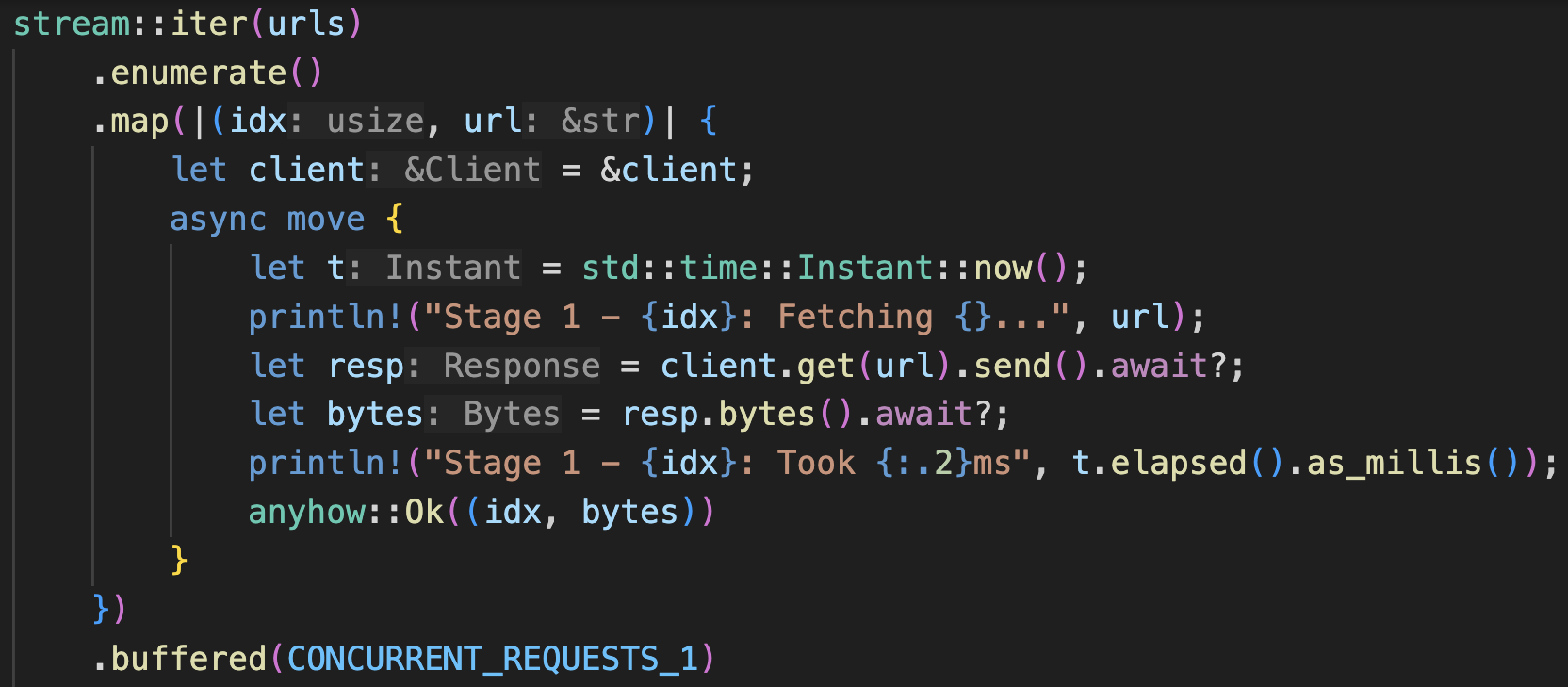
After the series on pools and pipeline (Part I, Part II) was published, a friend graciously pointed me to another approach that would be simpler for a lot of occasions with less boilerplate code. It uses the async Stream trait and its iterator-like adaptors in StreamExt. That Stack Overflow post was from 2018, but up till today (Jan 2024), the Stream trait is still not stablized into the Rust standard library. However, what worked back then still works today. It is so useful, and has become my go-to option in many cases. So let’s look at it together.
There are some good guides on streams123. Note that both the futures and Tokio crates have their own StreamExt utility traits and methods. As of today, futures’ implementation has a broader selection. We will be using some of them here.
At first, I was having a little hard time wrapping my head around streams. A Stream is the async-equivalent to an Iterator. Iterators are lazy, and they will get executed at the end of the method chain by methods like collect() and for_each(). Streams are lazier, compounded by the fact that Rust futures are lazy. This introduces another degree of freedom and complexity into the richness of Rust functional programming that iterators champion. Because of this, we are able to express concurrency and parallelism directly in the stream method chaining. In the sync land, you’d need Rayon to achieve parallelism (we’ll compare them a bit later).
Comment: Little did I know when writing this post, that the relationship between iterators and futures in Rust has a long history4, both of which are fundamentally driven by what defines the modern Rust programming language with a need for zero-cost abstraction. In addition, there exhibits some elegant symmetry between them56 (Maxwell’s Equations everyone?) These referenced articles were posted very recently (fresh off the Boats, sorry, can’t help it) and they are very relevant and insightful. So I would recommend a read if you are inclined to dig deeper.
In Part I of this mini-series, I implemented an actor pool pattern to perform IO-intensive pipeline jobs using the RPC model. The RPC model is relatively easy to program, because the main control flow code is together in one place, which abstracts away the dependencies as services. I don’t know about you, but this paradigm makes me feel like I’m following along in the life cycle of each task, and unless I send a request to some service, nothing moves. There is a psychological sense of safety to it… The biggest downside used to be spawning threads, which is expensive in synchronous programming. However, with async coroutines, it’s less of an issue.
The Streaming Model
Compare this with the streaming model. By that I mean the worker pool exposes send() and recv() methods, behaving like a processing queue. One single caller could keep calling send() sequentially, and tasks get sent off to the worker pool by a bounded input queue/channel and processed in parallel. The caller is not spawning anything but just sending messages. Then, the results would be sent to a bounded output queue within each worker. There is another coroutine/thread that catches the results from the output queue, like what we did in Part I. The queues are bounded, so the task sender feels the back pressure without needing a semaphore. When dealing with multiple worker pools in stages, we spin up connector coroutine/threads that carry tasks from last pool’s output queue to the next pool’s input queue. The input and output messages both contain unique markers, and we handle errors at the connectors and final output receiver.
How does this make you feel? It feels more dynamic and fluid to me, and the composition of the control flow is spread across connectors and receivers. However, this model maps more idiomatically to a pipeline with separate stages represented as boxes on a flow chart, and we imagine tasks flow through these boxes like a stream. It’s a more natural representation than the RPC model for data processing.
I am working on a Rust project that goes through a lot of small tasks in parallel. These tasks are primarily IO intensive, like downloading objects from S3, processing them, and storing the results somewhere else. Since this is a fairly representative use case in data engineering, I am keen on working out a generalized design pattern that can be customized to more scenarios. This post lays out such a pattern, and I will explain some of the specific considerations and choices made along the way.
In a distributed setting, there would be a global task queue to feed the inputs from a head node, a first-stage worker pool pulling tasks off the queue, and working through them in parallel. Then those workers would feed the outputs into another node-local queue, which connects to a second-stage worker pool to do some other parallel processing. The stages propagate, and each stage’s worker pool holds some special resources. When started and stabilized, the worker pools would run together and overlap the task execution between stages, benefiting from “pipeline parallelism”.
In the past, I would reach for Python to carry out this type of data pipelining. Due to its slowness and global interpreter lock (GIL), I had to jump through hoops to obtain multi-core usage to get decent throughput, and the resulting design was still riddled with thread contention, high memory usage, and unnecessary (de-)serialization if multiprocessing is used. If you are serious enough, you would probably want to use a distributed framework, like Dask, or Ray. They are all very useful, but I would like to make a case for single-node setups with a fast language - it’s flexible in iterative development and deployment, and it’s really efficient. Often, you don’t need a cluster, but just a node and some code to get similar throughput, especially when there are constraints at the source or the final destination.
The official release of the Rust AWS SDK was a final push for me. Since it’s using Tokio as its async runtime, and Tokio blends concurrency and multi-threaded parallelism together, it’s an ideal substrate for this work. Tokio also has smooth escape hatches in and out of the async world, so you know you are covered with the edge cases. In this post, we use the words “concurrent” and “parallel” in a similar vein, versus “sequential” / “serial”. However, There is an important but different angle to distinguish concurrency and parallelism regarding CPU cores, threads, and task scheduling.
I’ve been looking into training some big datasets (500GBs ~ several TBs) of small images with PyTorch. Previously, I have been using a really old and inflexible, but quite efficient format, MXNet’s MXIndexedRecordIO. But there are more and more problems with it. As datasets get larger, it takes a long time to pull to disk from wherever the data is stored, and during distributed training, every rank has to have a copy on disk. Indexed random access sucks a lot of IOPs from disks too, so you would need good disks. It takes a lot of conditions to be met to actually start training.
The industry moved fast to find its own solutions. Tensorflow users would use TFRecord. There is WebDataset, which is really just using tar files to store data in a certain way, and other libraries that support these formats. Essentially one would need to be able to stream the data, preferably in shards from the cloud, and train with window-shuffling as new chunks/shards are being downloaded.
Support for WebDataset has been slowly growing.
The original author’s implementation is pretty good, but there are some subtle areas that might trip users. The documentation has outdated parts, interweaved with up-to-date parts. But if you work through them, it’s a good solution.
TorchData, a PyTorch affiliate has full support over it. However recently it announced it had paused development because it needed to reevaluate the long-term vision.
Ray Data has an implementation and it was suggested to me during the recent Ray Summit. Although you would likely need to use the whole platform for it.
NVIDIA DALI supports the basic use of it, but apparently only loading from disk so far. One could however create an external source in Python. The advantage of DALI is doing image transforms/augmentations on GPUs in CUDA streams, taking the load off CPUs. Although usually CPUs are sufficient at simple-ish augs.
If you are like me (and many others), you’d need a strong reason to learn a new programming language (my journey). It’s a big commitment, and requires a lot of days and nights to do it right. Even for languages like Python that boast simplicity, under the hood there is a lot going on. For many developers, Python is the non-negotiable gluing/orchestrating layer that sits closest to them, because it frees them from the distractions that are not part of the main business logic, and has evolved to become the central language for ML/AI.
Rust on the other hand, requires a lot from a developer up front. Beyond a “hello world” toy example, it gets complex quickly, presenting a steep learning curve. It’s an amazing modern systems language, extremely fast and portable. However, my main programming activities have been in ML and data pipelines, operating on the Python (high) level, so I haven’t seriously tried to learn it.
Python’s ML and data story mostly revolves around the Python numeric ecosystem, which really took off when NumPy brought in the array interface and advanced math to become the “open-source researchers’ MATLAB”, that eventually kicked off almost 20 years of ML/AI development. Following that script, there emerged many Python-based workflows and packages that benefited from faster compiled languages as extension modules. They could be exploratory routines in scientific computing (physics, graphics, data analytics) that needed to be flexible yet efficient. They could be deep learning frameworks. They could also be distributed pipelines that ingest & transform large amounts of data, or web servers with heavy computation demands. The interoperating layer was fulfilled by Cython, SWIG, and Boost.Python. pybind11 grew as a successor to Boost.Python (different authors!) to offer C++ integration, and got good traction in late 2010.
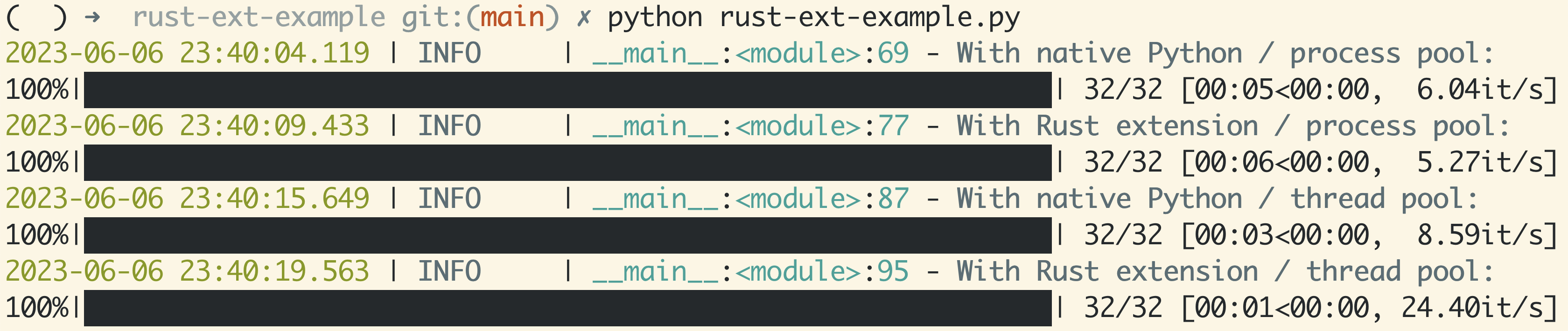
On the Rust side, PyO3 has been getting a lot of love. Developers love Rust’s safety guarantees, modern features, and excellent ecosystem, and have been leveraging ndarray, rust-numpy to interoperate with NumPy arrays from Python to speed up performance-critical sections of their code. This has tremendous appeal to me, and has granted me an overwhelming reason to learn Rust with the PyO3 + rust-numpy stack. Let this be my own “command line program” (from the Book) example. It wasn’t easy to get started this way… Took me through confusion, frustration, and finally, enlightenment in a short span of days. I hope this post can help you get started with your own journey.
Before pulling up the sleeves, let’s peek into Rust and PyO3’s ecosystem. PyO3 has great docs, which is much appreciated. I benefited a lot from the Articles section, reading about other developers’ journeys123. (Note: this article also joined the list!)
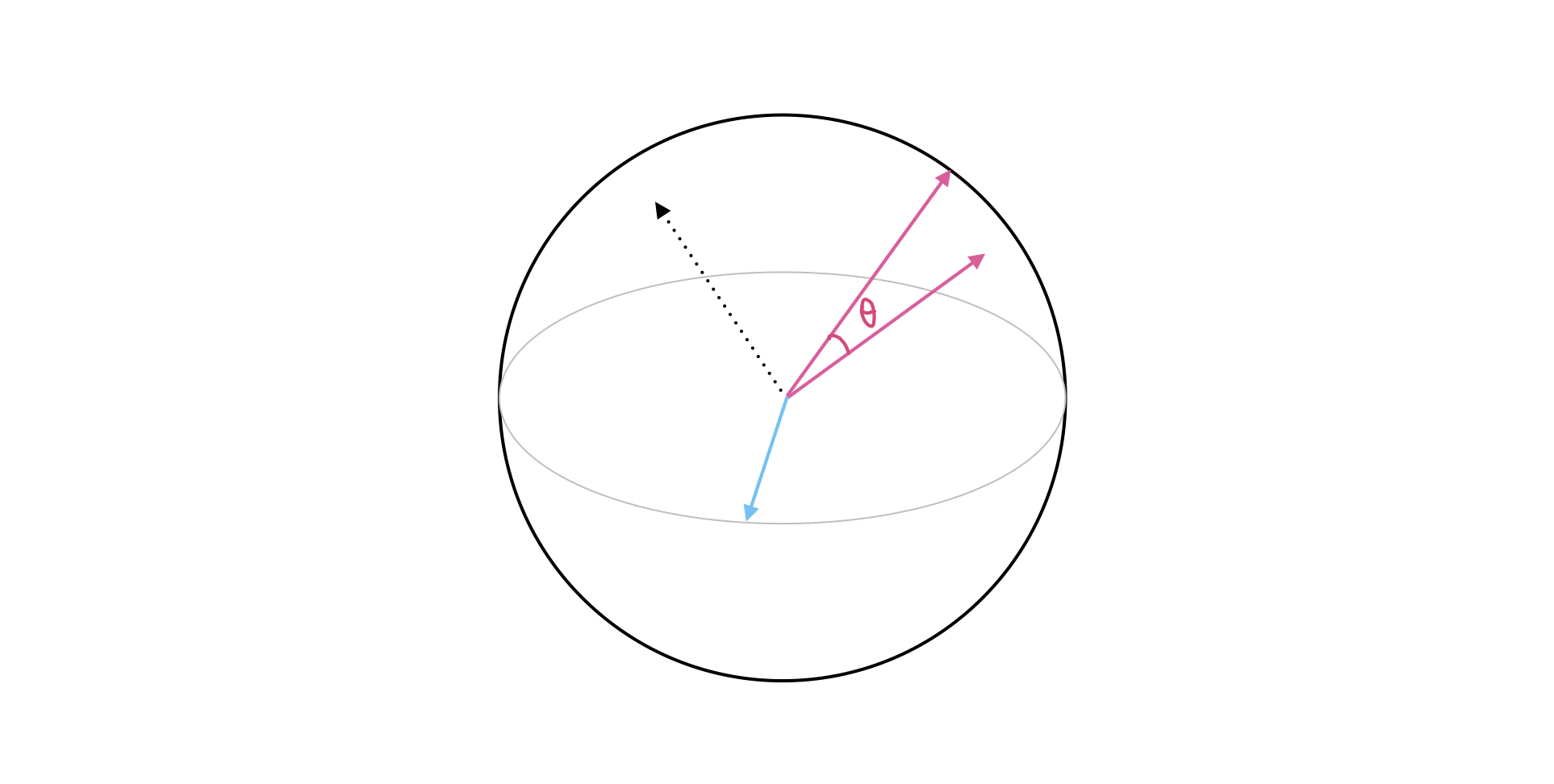
In this post, I would like to explore the idea of using embedding vectors to represent code snippets, and compute the cosine similarity scores between a few examples. I will compare OpenAI’s text-embedding-ada-002 with two open-source models, SantaCoder and Salesforce CodeGen. The OpenAI model was trained on general text data, but it’s the only embedding model the company currently offers. The other two models were trained on code to generate code, so we would need to do some hacking to get the embedding vectors.
How do we get the embedding vectors from a model? We can use the transformer part of the model to get the hidden states - layer-by-layer outputs of the transformer blocks. Thanks to a conversation with Vlad, I decided to use the last hidden state. The shape of this output is (batch_size, seq_len, hidden_size), so we would need to aggregate over the seq_len dimension to get the “summary”. We could take the mean, or max, or some other way. I tried the max, but the similarity scores looked all close to 1. So here let’s stick with the mean.
It is noteworthy to spell out the variety of choices here. Echoing my previous post, the embeddings from a generative model were not trained to definitively tell things apart.
I’ve long been curious but hesitant about using embedding vectors generated from pre-trained neural networks with self-supervision.
Coming from a brief but intense computer vision (CV) background, I can still remember the first bunch of deep learning tutorials were MNIST handwritten digits classification and ImageNet classification. Supervised learning with class labels, softmax, and cross-entropy loss was the standard formulation. Arguably it was facial recognition that pushed this formulation to the extreme. With tens of thousands of identities in the training set, telling the difference between them with certainty became difficult with the standard loss function. So instead of using softmax and cross-entropy loss, practitioners resorted to the contrastive loss formulation, such as triplet loss in the FaceNet paper. The intra-class features from this method were grouped together, while inter-class separated afar, exhibiting strong discriminative power.
The stars are aligned. I finally sat down and went through “the book.”
I tweaked the color combo to “Rust” and went through the first eight chapters slowly and carefully, ending in Common Collections and, in addition, Chapter 15. Smart Pointers. Typically learning to program is best to be hands-on for me, coupled with many random detours. However, I found the structure and flow of this book very helpful, explaining the necessary details while staying in context, and I enjoyed following its lead. I would attribute this partly to the writing style, with focused code demonstrations iteratively simulating the debugging process one would go through themselves. One would also realize it’d be necessary to sit through the “lecture” sections before preemptively getting hands dirty in an editor with Rust because of the philosophy and design decisions that led to the creation of this language - they need more words to be clear.
I originally intended to leave this as a short paragraph, in the middle of a thought piece after learning Rust for a week. But the abbreviated turned fully expanded. So here it is.
This is my personal programming journey. I learned a tiny bit of Pascal in high school around 2005, but focused more on playing Counter-Strike and making maps (more productive than being just a gamer?). We were required to learn C in college, but I hated it because exams were intentionally trying to trick us into memorizing syntax quirks. I started seriously learning Python (with A Byte of Python) and Linux in 2012 in grad school for scientific computing needs. It was also around that time when the Python scientific ecosystem really started to flourish, with data science and machine learning on the rise, attracting a lot of cash in the industry. Python is a very intuitive language with plain English-like syntax (progressive disclosure of complexity) and easy-to-expect behaviors. It abstracts much complexity away from novice users, so they won’t have to worry about resource management and automatically get memory-safety guarantees. Its standard library and ecosystem are vast, and you can almost always find something other people created and start using them for your needs after simple installation steps. It accomplishes these tasks at the cost of performance - it is dynamically typed with an interpreter, garbage collected, and comes with a global interpreter lock (GIL for the dominant CPython at least). Many workarounds include interfacing with a lower-level language (C/C++) to get intrinsic speed and multithreading without the GIL. With enough care, you can usually get around the bottlenecks at hand and find new bottlenecks to be something else in a compute-centric system. Python is a T-shaped language.
I recently came across an article by Andrej Karpathy, ex-Sr. Director of AI at Tesla. Besides being impressed by the content, I was almost brought to tears. So much of it was what I personally experienced, learned the hard way, came to believe in, and decided to teach others. It felt vindicating to hear him say
…a “fast and furious” approach to training neural networks does not work and only leads to suffering… the qualities that in my experience correlate most strongly to success in deep learning are patience and attention to detail.
because I kept saying this but this point and its implications weren’t going through people’s minds.
Here I offer some of my own rules of training deep learning models. It might end up being a growing list.
This is a quick note on how to use openmp or rather, any multithreading library to divide the underlying data. Let’s use some code snippets from Faiss.
Usually you would parallel for, or first parallel then for over a sequence. For example:
intnt=std::min(omp_get_max_threads(),int(n));#pragma omp parallel for if (nt > 1)
for(idx_tslice=0;slice<nt;slice++){IndexIVFStatslocal_stats;idx_ti0=n*slice/nt;idx_ti1=n*(slice+1)/nt;
I came across a different use case that was note-worthy:
For people who fool around in the small field of Approximate Nearest Neighbors (ANN) search, Faiss and hnswlib are two big names. Faiss is a much broader library with a lot of in-memory ANN methods, vector compression schemes, GPU counterparts, and utility functions, whereas hnswlib is a lot more specific, with only one graph-based in-memory index construction method called Hierarchical Navigable Small Worlds (HNSW)12. After the open-source implementation of HNSW in hnswlib came out, Faiss also attempted it with its IndexHNSW class.
Which to pick? Being a long-time Faiss user, I had the natural inclination to keep using what it offered. However, issues ensued.
Not every business needs a Research function, certainly not every startup. However if a startup’s bread and butter is advanced technology, a sustained effort has to be put into maintaining it and cutting out new paths. The Research function’s role is to tease and trek into the unknown, to distill the craft into our potential area of expertise. In fulfilling this function, it needs to be comfortable not knowing how the piece of technology exactly fits into the product timeline and coordination - if we are confident in specing out even the big strokes at the beginning, it’s not research but engineering execution. Instead, it needs to do the following things.
It needs to identify and appreciate a big challenge, take comfort and joy in the craft itself, and recognize the fact that the problem is meaningful enough that any findings coming out of it could shape key directions for the business.
It needs to formulate hypotheses, set up environments to prove or disprove them quickly in the most representative yet still efficient way, and change course quickly in a matter of days and weeks. The code written and tools built during the many fail-fast attempts do not get thrown away, but factored into common elements and components in a broad collection of Swiss army knives that can be repurposed easily.
It needs to be fixated on the important details, retain a long working memory, turn every stone and record them, and aim to incrementally become an expert on the subject.
It needs to identify milestones particular to the different branching points, systematically approach them in overlapping time frames, and have the will to drive through to the conclusion.
You learned about this in college classes. You thought working SWE jobs in 2022 you’d never have to deal with this. But it comes back to trick you at your worst.
I was tripped by endian-ness when implementing inverted list listno-offset/LO as a fixed-width byte string key in RocksDB.
// When offsets list id + offset are encoded in an uint64// we call this LO = list-offsetinlineuint64_tlo_build(uint64_tlist_id,uint64_toffset){returnlist_id<<32|offset;}inlineuint64_tlo_listno(uint64_tlo){returnlo>>32;}inlineuint64_tlo_offset(uint64_tlo){returnlo&0xffffffff;}