Big Data Engineering in the 2020s - One Big Machine
Jun 30, 2024
I wanted to write this post after juggling PBs of (non-tabular) data in the past year at work, and having experienced first-hand how amazing the Big Data landscape is morphing into in the mid-2020s. The ground is shifting under our feet, and individuals & small teams are immensely empowered with recent advances in hardware capabilities, accessible infrastructure, and modern software tooling. I would like to reaffirm that, as data practitioners we totally could, and should do serious work on one single big machine on a good cloud platform, and weigh the pros and cons of adopting abstractions carefully in case of scaling out. We don’t have to be impeded by the idea that Big Data has to be solved by a cluster of machines through distributed computing, thus out of reach for most developers. I will also lay out a minimally viable way to linearly scale out the occasional data processing needs, which can be particularly helpful for non-tabular data, where unified frameworks are still lacking.
Note: The workload described in this post is non-taublar data, usually revolving around big bespoke formats, raw media files, and ML records with binary data and tensors/arrays. Unlike tabular data with tens of popular cluster solutions, working with non-tabular data is more ad hoc. If you work with tabular data, and need to frequently do aggregation or training with columns of data, existing data warehouse and data lake solutions are quite advantageous.
In the past 10 years, a couple of major changes took place in computing:
- Computing power per machine continued to grow, not through higher clock frequencies, but by inventing advanced instruction sets (e.g. SIMD), and packing more CPU cores and memory chips. It’s commonplace to see machines with 100+ cores and TBs of memory. What used to be achievable only by a cluster of machines now can be accessed by one single node. Similar things happened to accelerated computing, e.g. GPUs.
- Cloud platforms have become commodities, with higher accessibility to a variety of instance types, resources, and predictable & ever-lowering costs. Users also have easy access to high network bandwidth, and near-infinite reliable cloud object storage that speaks S3 with high throughput. For example, you could get an instance from major cloud providers with 128 cores, 1 TB of memory, 30 TB of NVMe low-latency local storage, and 75 Gibps of network bandwidth for $10/hr.
- Memory-safe systems programming languages became more mature and gained wide adoption, notably Rust. This enabled close-to-metal performance and utilization of modern processors’ parallel architectures. There emerged a proliferation of native tooling to tackle Big Data problems.
- An important side effect of the wider systems languages adoption was high-level dynamic languages benefiting substantially from native extensions written in those languages. A Python programmer can easily access extreme performance otherwise not accessible before. Since Python has become the de facto language for ML/AI used by millions of people, this “upcast” dramatically extended those projects’ reach, as well as developers’ abilities. Examples: for tabular data, DuckDB, Polars, PyArrow, Delta Lake, for vector data, Faiss, hnswlib. New promising format: LanceDB.
Use One Big Machine!
Now, let us look at the benefits of using one single machine to do data work:
- It is easy to spin up and down, scale up and down with different combinations of resources by switching VMs on the same cloud platform, attaching and detaching the same volume that hosts your code and key data. This keeps the cost to roughly just what you need.
- It is easy to stay organized for code and key data, without needing to track multiple copies and sync between them. This results in less mental load and operational overhead. Data engineering is a very interactive type of work, which requires constant feedback running code on a portion of the actual data, handling errors that pop up, and observing live logs to ensure final success. As you move data, your code moves with them, oftentimes at a higher frequency due to tweaks to user interfaces, logging messages, etc. It’s paramount to stay sane and sanitize your memory of the steps you take and events that take place.
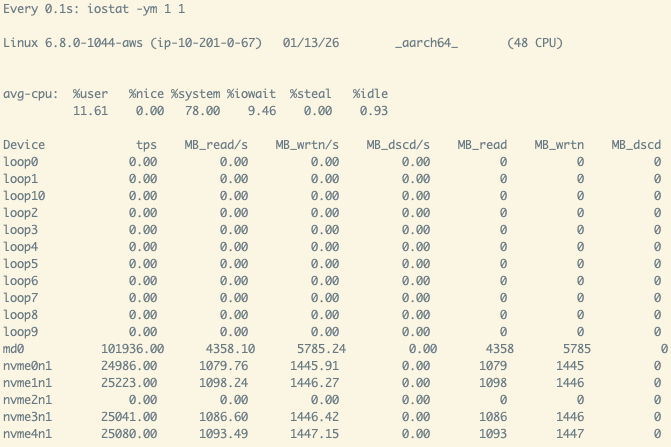
- It has less complexity and is easier to program than a cluster of machines. The unit substrate of programming is typically one machine. So we get the full support from the ecosystem around us. Deployment is easier, without paying for containerization when you don’t need it. It’s also easier to plan resource utilization within the single-node model for CPUs, memory, storage, and networking. Observability is also much easier, just a few Linux commands away (
htop,iostat,nload, etc.) - You get organic data locality for passing between processes & services through the loopback interface on the same host, without networking overhead. You are also encouraged to use threading that shares memory, or use shared memory (zero-copy memory layout, like a simple array, Arrow, dlpack for GPU tensors) between processes to avoid unnecessary copies and de-/serialization, thus getting peak speed.
 |
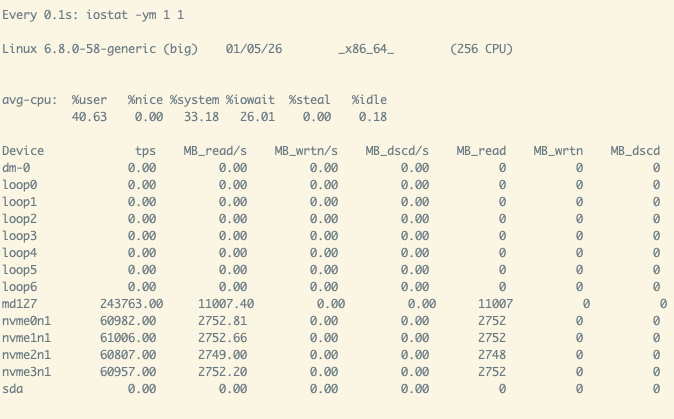 |
With one single machine, you are bound by the CPU, memory, storage IOPS/throughput and network limits of the largest instance you could get on a given cloud platform. However, empowered by systems languages for native performance, you could lift a tremendous amount of data under those limits in a short duration of time, typically faster than the time for you to do the actual programming! Aim at 5~10 GB/s for storage/network throughput saturation, you could go through 400~800 TB of data a day!
 |
 |
Another important consequence of this high ceiling is it shortens the duration of your average stage of work in a long sequence down to minutes and hours, instead of days and weeks. Minutes and hours are within our attention span and context window, while days and weeks are not. Tasks that used to need to explicitly plan for, now are a matter of a lunch break, or as long as a night of sleep during off hours. It is an incredible productivity boost, and puts control and value back onto the developers, instead of machines.
You are also bound by immediate storage limits, but this is not a problem if your data could be chunked, and synced to/from cloud object storage. Of course, you need a toolkit that could saturate network bandwidth to prosper (e.g. AWS Rust SDK, official in Nov 2023). For data that can’t be chunked, usually you put them in a cluster of database nodes that are well-optimized with established interfaces.
Scaling Out
What about the times you actually need to scale out work to multiple machines? There are many cases for this: compute heavy workload, accelerated chips (GPUs) needed, or simply bargaining with some per-IP address rate/connection limiting mechanism from external services. Here is an approachable recipe to scale out linearly, assuming auth & permission control is not an issue (some environments are insulated from prod, thus satisfying this assumption):
- Don’t pay orchestration and abstraction costs if you don’t need it. This means you don’t have to start with Kubernetes, or even containerization. It’s just you, your one single node, a code repository somewhere, and some networking setup.
- Create a repository, with some control scripts that set up the remote machines through
ssh,rsync, and idempotent scripts containing standard Linux command line instructions, that get executed remotely. If you are doing distributed computing, you are going to mess with system resources configuration anyway, and those abstractions are usually incomplete (custom drivers, swap space, ephemeral disk mounts, to name a few), let alone a whole separate thing to learn. Just use your one single node as the “head node”, and set the worker nodes up. Make sure you can run the setup script multiple times without ill effects. Make sure you sync whatever you need to the workers, anticipating worker VM’s OS varieties. Do somesystemd-fu so you can remote control or auto-start worker processes. - You could opt in containerization, and set up a container registry to sync over the container images. This makes deployment a lot more predictable, but you pay the cost of pushing a new version with every incremental change. You should weigh the cost and benefit.
- See if your data could be chunked in large units. When units of work are big, like batches of tens of thousands of smaller units, it’s easier and more efficient to store, list, and transfer. Your downstream derivative data will also map nicely to those bigger chunks, maintaining logical consistency and sanity. Lots of data sources that need intensive computation could satisfy this criterion.
- You could have a manifest of those big chunks of data on your head node, set up the worker nodes, and dispatch only slim “pointer-like” file/object names/paths through a simple Redis list, or Stream (could be on your head node). Workers download from object storage, do work, and upload to a different location, or send back through a different Redis list. Tasks indicate success by uploading/sending their results to the final destination. Your head node can control and monitor those workers, and check work progress. You check the manifest, and resend the diffs for failed tasks, or automatically harvest the failed tasks until complete success.
- By doing the above, you make each task a stateless unit of work, and thus enable a fail-able design pattern for batch processing. This also lets you use cheaper preemptable/spot instances, which usually are 1/3 of their full prices. It can scale out linearly, until bottlenecked by external factors, like total bandwidth of your physical worker group, or source/destination cloud storage account-level allowable throughput, if any. The sky is the limit.
- This is the smallest amount of cost you need to pay to blast through PBs of data in 5~10 days, and you or your small team can coordinate this without much overhead. There is no unreliable abstraction out of your control, that could trap you or make you submit some ticket or issue to get handled by companies that built those products. Some tricky OS-level config that requires a bespoke setup? Easy - just add a line using command line tools, like how you’d do it on a single machine.
- If your major programming language is Python, or you could readily create native extensions and integrate with Python, you could also opt in Ray, or Dask. It takes care of a lot of coordination for you, backed by a sound and efficient distributed computing design.
The progress in computing and data is incredible to witness. What will happen next?