Kids! Use hnswlib for HNSW
28 Sep 2022 Comments
For people who fool around in the small field of Approximate Nearest Neighbors (ANN) search, Faiss and hnswlib are two big names. Faiss is a much broader library with a lot of in-memory ANN methods, vector compression schemes, GPU counterparts, and utility functions, whereas hnswlib is a lot more specific, with only one graph-based in-memory index construction method called Hierarchical Navigable Small Worlds (HNSW)1 2. After the open-source implementation of HNSW in hnswlib came out, Faiss also attempted it with its IndexHNSW class.
Which to pick? Being a long-time Faiss user, I had the natural inclination to keep using what it offered. However, issues ensued.
So I whipped up a large HNSW index with scalar quantization (SQ) HNSW32,SQ8, 512 dimensions, ~30M vectors, with efConstruction=100. It amounted to a little over 20GB in size. The general setup was a cloud instance with 32 physical cores and 64 hyperthreads and 120GB ~ 590GB memory, but a smaller or larger config would yield similar outcomes. I also experimented with both Intel and AMD, Ubuntu and RHEL-based OSes, so what I saw should be representative. Note the CPUs all supported AVX512 and less instructions.
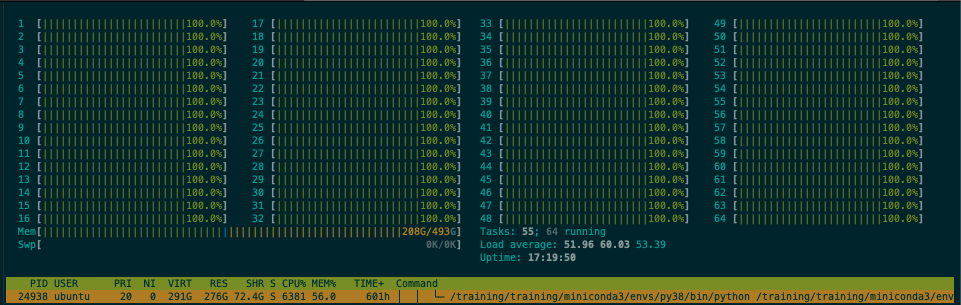
Initially, everything was fine, all cores/threads firing 100% (green in htop meaning all user threads), and memory usage stable. As I kept adding new vectors into it, suddenly, around ~25GB in size, ~30M vectors, searches became twice to three times slower. The CPU utilization was less than total thread count, and there was a lot of red in htop indicating kernel threads firing. The resident memory started fluctuating within a 3GB range. The above screenshot depicts the CPU usage issue, red kernel threads dominating the green user threads, which used to be almost 100% when the index was smaller/fewer vectors.
I checked the SSD, not much IO, and there was no swap set up. All were indicating memory access pattern issues. I found this article about Transparent Hugepage Support, that some databases such as MongoDB and Postgres did not like it to be enabled. However, my situation actually improved if I went the opposite way and enabled always to THP, instead of madvise. Speed went up by about 1.5x, but there was still a lot of kernel threads activity, and memory still fluctuating.
If I had to guess, it was probably tweakable through some OS setting related to memory and caching. But how could I best debug and analyze the issue? I was informed by the Faiss author Matthijs Douze, that I should try the original/reference implementation from hnswlib.
Here is a side-by-side comparison using full precision float32 vectors. Both were benchmarked through bindings using Python 3.8. Faiss 1.7.2 was installed from the Anaconda pytorch channel with AVX2 support, and hnswlib 0.6.2 was compiled with native flag enabling AVX512 support.
In []: import numpy as np
In []: import time
In []: import hnswlib
In []: import faiss
In []: data = np.load("data.npy", mmap_mode="r")
# hnsw add
In []: num_elements = data.shape[0]
In []: ids = np.arange(num_elements)
In []: p = hnswlib.Index(space = 'ip', dim = 512)
In []: p.init_index(max_elements = num_elements, ef_construction = 200, M = 32)
In []: t = time.time(); p.add_items(data, ids); print(time.time() - t)
11217.803444623947
In []: p.max_elements
Out[]: 37949877
In []: p.set_ef(2048)
In []: %timeit p.knn_query(data[:10000], 5)
22.2 s ± 30.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# Faiss add
In []: quantizer = faiss.index_factory(512, "HNSW32", faiss.METRIC_INNER_PRODUCT)
In []: quantizer.hnsw.efConstruction = 200
In []: t = time.time(); quantizer.add(xb); print(time.time() - t)
21627.71038222313
In []: quantizer.ntotal
Out[]: 37949877
In []: quantizer.hnsw.efSearch = 2048
In []: %timeit quantizer.search(data[:10000], 5)
2min 42s ± 3.48 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
This was what CPU usage looked like in htop for hnswlib:
And this for Faiss HNSW32:
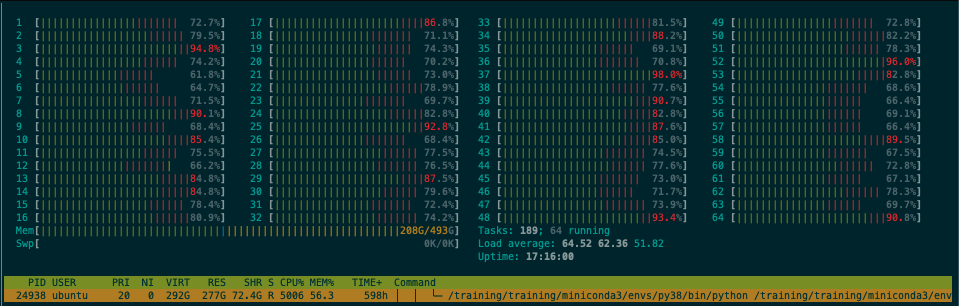
Compare hnswlib’s 22s with Faiss IndexHNSW’s 2min42s. That was a huge difference.
Why? I thought first off there were confounding factors - CPU advanced instruction sets. The float32 implementation in hnswlib was at an advantage because it fully utilized AVX512, whereas in Faiss it used AVX at best (here, here, and here). These powerful vectorization techniques would make a lot of difference in numerical computations.
To highlight this factor, I did some single-core benchmarking at the same param settings with float32 vectors. I did not observe kernel thrashing (red in htop) so the difference must have been mostly due to advanced instruction sets. Faiss’s search queries took ~1.72x (quite consistently) those of hnswlib.
In [58]: p.set_num_threads(1)
In [59]: faiss.omp_set_num_threads(1)
In [60]: %timeit p.knn_query(data[:10], 5)
320 ms ± 1.65 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [61]: %timeit quantizer.search(data[:10], 5)
552 ms ± 9.09 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [62]: %timeit p.knn_query(data[:50], 5)
1.69 s ± 3.37 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [63]: %timeit quantizer.search(data[:50], 5)
2.92 s ± 43.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Assuming this factor would stay the same for fully threaded use, the rest of the difference still needed an explanation. In my earliest experiment with Faiss HNSW,SQ8, which made use of AVX2 instructions, the slowness and kernel thrashing behavior were still present. It was when I encountered this problem in the first place.
My strongest hypothesis was that it was due to the way IndexHNSW variants were implemented, with actual vector storage separate from the HNSW graph structure. Memory was supposed to be fast, but somehow the access pattern did not play well with this type of separation. hnswlib did not adopt this pattern, so it was able to operate at peak capacity.
This seems to be a bummer, because it was such an elegant way to implement the graph structure/storage separation. But it’s probably wise to use the original hnswlib implementation for max performance for the time being. Note it’s not impossible to take Faiss’s compression schemes and apply them to hnswlib, although you need to implement convenient training and metadata dumping/loading to make it more flexible.
This issue was reported by my other account. Looking forward to someone fixing the problem.