06 Jan 2024
You can check out the code here.
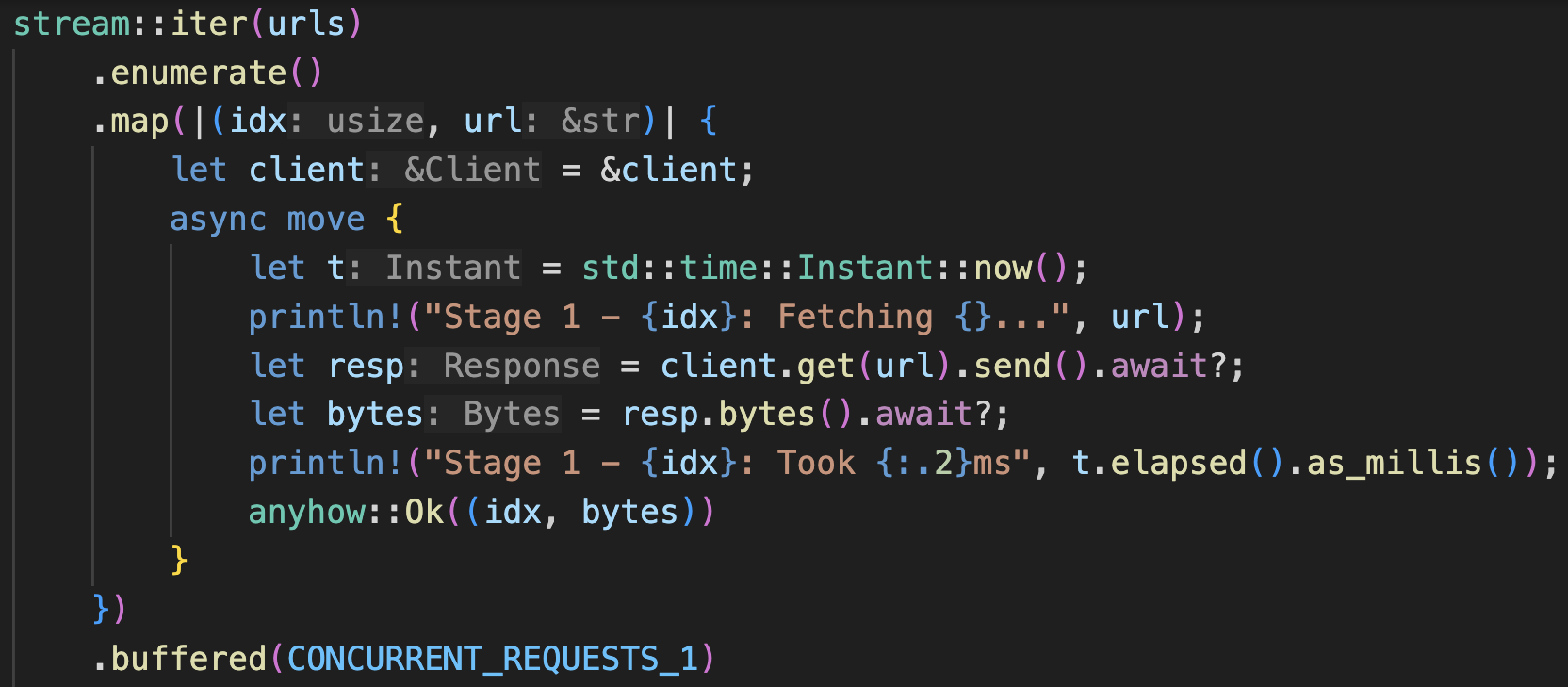
After the series on pools and pipeline (Part I, Part II) was published, a friend graciously pointed me to another approach that would be simpler for a lot of occasions with less boilerplate code. It uses the async Stream trait and its iterator-like adaptors in StreamExt. That Stack Overflow post was from 2018, but up till today (Jan 2024), the Stream trait is still not stablized into the Rust standard library. However, what worked back then still works today. It is so useful, and has become my go-to option in many cases. So let’s look at it together.
There are some good guides on streams . Note that both the futures and Tokio crates have their own StreamExt utility traits and methods. As of today, futures’ implementation has a broader selection. We will be using some of them here.
At first, I was having a little hard time wrapping my head around streams. A Stream is the async-equivalent to an Iterator. Iterators are lazy, and they will get executed at the end of the method chain by methods like collect() and for_each(). Streams are lazier, compounded by the fact that Rust futures are lazy. This introduces another degree of freedom and complexity into the richness of Rust functional programming that iterators champion. Because of this, we are able to express concurrency and parallelism directly in the stream method chaining. In the sync land, you’d need Rayon to achieve parallelism (we’ll compare them a bit later).
Comment: Little did I know when writing this post, that the relationship between iterators and futures in Rust has a long history, both of which are fundamentally driven by what defines the modern Rust programming language with a need for zero-cost abstraction. In addition, there exhibits some elegant symmetry between them (Maxwell’s Equations everyone?) These referenced articles were posted very recently (fresh off the Boats, sorry, can’t help it) and they are very relevant and insightful. So I would recommend a read if you are inclined to dig deeper.
Read more...
28 Dec 2023

You can check out the code here.
In Part I of this mini-series, I implemented an actor pool pattern to perform IO-intensive pipeline jobs using the RPC model. The RPC model is relatively easy to program, because the main control flow code is together in one place, which abstracts away the dependencies as services. I don’t know about you, but this paradigm makes me feel like I’m following along in the life cycle of each task, and unless I send a request to some service, nothing moves. There is a psychological sense of safety to it… The biggest downside used to be spawning threads, which is expensive in synchronous programming. However, with async coroutines, it’s less of an issue.
The Streaming Model
Compare this with the streaming model. By that I mean the worker pool exposes send() and recv() methods, behaving like a processing queue. One single caller could keep calling send() sequentially, and tasks get sent off to the worker pool by a bounded input queue/channel and processed in parallel. The caller is not spawning anything but just sending messages. Then, the results would be sent to a bounded output queue within each worker. There is another coroutine/thread that catches the results from the output queue, like what we did in Part I. The queues are bounded, so the task sender feels the back pressure without needing a semaphore. When dealing with multiple worker pools in stages, we spin up connector coroutine/threads that carry tasks from last pool’s output queue to the next pool’s input queue. The input and output messages both contain unique markers, and we handle errors at the connectors and final output receiver.
How does this make you feel? It feels more dynamic and fluid to me, and the composition of the control flow is spread across connectors and receivers. However, this model maps more idiomatically to a pipeline with separate stages represented as boxes on a flow chart, and we imagine tasks flow through these boxes like a stream. It’s a more natural representation than the RPC model for data processing.
Read more...
27 Dec 2023

You can check out the code here.
I am working on a Rust project that goes through a lot of small tasks in parallel. These tasks are primarily IO intensive, like downloading objects from S3, processing them, and storing the results somewhere else. Since this is a fairly representative use case in data engineering, I am keen on working out a generalized design pattern that can be customized to more scenarios. This post lays out such a pattern, and I will explain some of the specific considerations and choices made along the way.
In a distributed setting, there would be a global task queue to feed the inputs from a head node, a first-stage worker pool pulling tasks off the queue, and working through them in parallel. Then those workers would feed the outputs into another node-local queue, which connects to a second-stage worker pool to do some other parallel processing. The stages propagate, and each stage’s worker pool holds some special resources. When started and stabilized, the worker pools would run together and overlap the task execution between stages, benefiting from “pipeline parallelism”.
In the past, I would reach for Python to carry out this type of data pipelining. Due to its slowness and global interpreter lock (GIL), I had to jump through hoops to obtain multi-core usage to get decent throughput, and the resulting design was still riddled with thread contention, high memory usage, and unnecessary (de-)serialization if multiprocessing is used. If you are serious enough, you would probably want to use a distributed framework, like Dask, or Ray. They are all very useful, but I would like to make a case for single-node setups with a fast language - it’s flexible in iterative development and deployment, and it’s really efficient. Often, you don’t need a cluster, but just a node and some code to get similar throughput, especially when there are constraints at the source or the final destination.
The official release of the Rust AWS SDK was a final push for me. Since it’s using Tokio as its async runtime, and Tokio blends concurrency and multi-threaded parallelism together, it’s an ideal substrate for this work. Tokio also has smooth escape hatches in and out of the async world, so you know you are covered with the edge cases. In this post, we use the words “concurrent” and “parallel” in a similar vein, versus “sequential” / “serial”. However, There is an important but different angle to distinguish concurrency and parallelism regarding CPU cores, threads, and task scheduling.
Read more...
29 Sep 2023
I’ve been looking into training some big datasets (500GBs ~ several TBs) of small images with PyTorch. Previously, I have been using a really old and inflexible, but quite efficient format, MXNet’s MXIndexedRecordIO. But there are more and more problems with it. As datasets get larger, it takes a long time to pull to disk from wherever the data is stored, and during distributed training, every rank has to have a copy on disk. Indexed random access sucks a lot of IOPs from disks too, so you would need good disks. It takes a lot of conditions to be met to actually start training.
The industry moved fast to find its own solutions. Tensorflow users would use TFRecord. There is WebDataset, which is really just using tar files to store data in a certain way, and other libraries that support these formats. Essentially one would need to be able to stream the data, preferably in shards from the cloud, and train with window-shuffling as new chunks/shards are being downloaded.
Support for WebDataset has been slowly growing.
- The original author’s implementation is pretty good, but there are some subtle areas that might trip users. The documentation has outdated parts, interweaved with up-to-date parts. But if you work through them, it’s a good solution.
- TorchData, a PyTorch affiliate has full support over it. However recently it announced it had paused development because it needed to reevaluate the long-term vision.
- Ray Data has an implementation and it was suggested to me during the recent Ray Summit. Although you would likely need to use the whole platform for it.
- NVIDIA DALI supports the basic use of it, but apparently only loading from disk so far. One could however create an external source in Python. The advantage of DALI is doing image transforms/augmentations on GPUs in CUDA streams, taking the load off CPUs. Although usually CPUs are sufficient at simple-ish augs.
I am currently switching between the original author’s impl and the TorchData impl. They work reasonably well for my use case. The challenge has been handling interaction between distributed/multiprocessing and shard splitting. There are many GitHub issues around it, and the documentations are not written for users who just want to shuffle and feed data correctly. Essentially, in the WebDataset scheme, the data shards are treated as coarse indexes, and it requires some finessing to have all ranks receive the same number of batches to synchronize, and not lose some of the data.
These two libraries evolved with each other’s influence, and made a lot of genius use of iterators and all kinds of iterator functions. It’s kind of a nod to Rust’s wide support for iterators.
Another solution for small files and images is Parquet, which also has broad support. The challenge is it’s such a flexible format, so one has to read within fine print to see what the library handles, and what you need to handle. Luckily, with data loading during training, the bottleneck is usually the GPU compute part, and even if ad-hoc custom plugins are slowish, it’s still not a big problem.
Just jotting down notes in case others are wondering.
Read more...
06 Jun 2023
This post is a more hands-on sequel to my beginner article about getting to learn Rust. You can check out the code here.
If you are like me (and many others), you’d need a strong reason to learn a new programming language (my journey). It’s a big commitment, and requires a lot of days and nights to do it right. Even for languages like Python that boast simplicity, under the hood there is a lot going on. For many developers, Python is the non-negotiable gluing/orchestrating layer that sits closest to them, because it frees them from the distractions that are not part of the main business logic, and has evolved to become the central language for ML/AI.
Rust on the other hand, has a lot going on up front. Beyond a “hello world” toy example, it is particularly good at building, e.g. command line programs, because it’s a great modern systems language, extremely fast and portable. However, my main programming activities have been in ML and data pipelines.
This mostly revolves around the Python numeric ecosystem, which really took off when NumPy brought in the array interface and advanced math to become the “open-source researchers’ MATLAB”, that eventually kicked off almost 20 years of ML/AI development. Following that script, there emerged many Python-based workflows and packages that benefited from faster compiled languages as extension modules. They could be exploratory routines in scientific computing (physics, graphics, data analytics) that needed to be flexible yet efficient. They could be deep learning frameworks. They could also be distributed pipelines that ingest & transform large amounts of data, or web servers with heavy computation demands. The interoperating layer was fulfilled by SWIG, Cython, and Boost.Python. pybind11 grew as a successor to Boost.Python (different authors!) to offer C++ integration, and got good traction in late 2010.
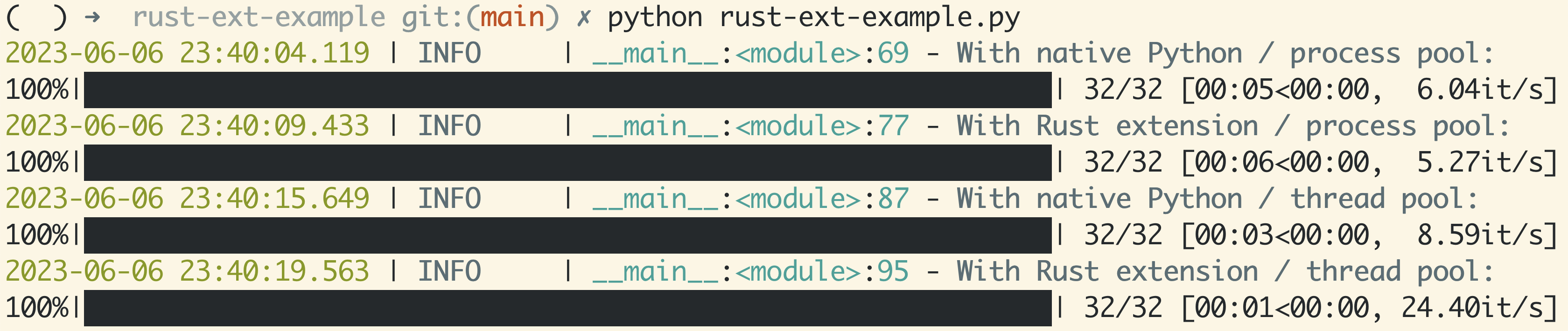
On the Rust side, PyO3 has been getting a lot of love. People love Rust’s safety guarantees, modern features, and excellent ecosystem, and have been leveraging ndarray, rust-numpy to interoperate with NumPy arrays from Python to speed up performance-critical sections of their code. This has tremendous appeal to me, and has granted me an overwhelming reason to learn Rust with the PyO3 + rust-numpy stack. Let this be my own “command line program” example. It wasn’t easy to get started this way… Took me through exhilaration, confusion, frustration, and finally, enlightenment in a short span of days. I hope this post can help you get started with your own journey.
Before pulling up the sleeves, let’s peek into Rust and PyO3’s ecosystem. PyO3 has great docs, which is much appreciated, but a common practice with Rust crates. I benefited a lot from the Articles section, reading about other developers’ journeys . (Note: this article also joined the list!)
Read more...
18 Apr 2023
In this post, I would like to explore the idea of using embedding vectors to represent code snippets, and compute the cosine similarity scores between a few examples. I will compare OpenAI’s text-embedding-ada-002 with two open-source models, SantaCoder and Salesforce CodeGen. The OpenAI model was trained on general text data, but it’s the only embedding model the company currently offers. The other two models were trained on code to generate code, so we would need to do some hacking to get the embedding vectors.
Setup
from itertools import combinations
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
How do we get the embedding vectors from a model? We can use the transformer part of the model to get the hidden states - layer-by-layer outputs of the transformer blocks. Thanks to a conversation with Vlad, I decided to use the last hidden state. The shape of this output is (batch_size, seq_len, hidden_size), so we would need to aggregate over the seq_len dimension to get the “summary”. We could take the mean, or max, or some other way. I tried the max, but the similarity scores looked all close to 1. So here let’s stick with the mean.
It is noteworthy to spell out the variety of choices here. Echoing my previous post, the embeddings from a generative model were not trained to definitively tell things apart.
Read more...
17 Apr 2023
I’ve long been curious but hesitant about using embedding vectors generated from pre-trained neural networks with self-supervision.
Coming from a brief but intense computer vision (CV) background, I can still remember the first bunch of deep learning tutorials were MNIST handwritten digits classification and ImageNet classification. Supervised learning with class labels, softmax, and cross-entropy loss was the standard formulation. Arguably it was facial recognition that pushed this formulation to the extreme. With tens of thousands of identities in the training set, telling the difference between them with certainty became difficult with the standard loss function. So instead of using softmax and cross-entropy loss, practitioners resorted to the contrastive loss formulation, such as triplet loss in the FaceNet paper. The intra-class features from this method were grouped together, while inter-class separated afar, exhibiting strong discriminative power.
Read more...
21 Mar 2023
The stars are aligned. I finally sat down and went through “the book.”
I tweaked the color combo to “Rust” and went through the first eight chapters slowly and carefully, ending in Common Collections and, in addition, Chapter 15. Smart Pointers. Typically learning to program is best to be hands-on for me, coupled with many random detours. However, I found the structure and flow of this book very helpful, explaining the necessary details while staying in context, and I enjoyed following its lead. I would attribute this partly to the writing style, with focused code demonstrations iteratively simulating the debugging process one would go through themselves. One would also realize it’d be necessary to sit through the “lecture” sections before preemptively getting hands dirty in an editor with Rust because of the philosophy and design decisions that led to the creation of this language - they need more words to be clear.
Read more...
20 Mar 2023
I originally intended to leave this as a short paragraph, in the middle of a thought piece after learning Rust for a week. But the abbreviated turned fully expanded. So here it is.
This is my personal programming journey. I learned a tiny bit of Pascal in high school around 2005, but focused more on playing Counter-Strike and making maps (more productive than being just a gamer?). We were required to learn C in college, but I hated it because exams were intentionally trying to trick us into memorizing syntax quirks. I started seriously learning Python (with A Byte of Python) and Linux in 2012 in grad school for scientific computing needs. It was also around that time when the Python scientific ecosystem really started to flourish, with data science and machine learning on the rise, attracting a lot of cash in the industry. Python is a very intuitive language with plain English-like syntax (progressive disclosure of complexity) and easy-to-expect behaviors. It abstracts much complexity away from novice users, so they won’t have to worry about resource management and automatically get memory-safety guarantees. Its standard library and ecosystem are vast, and you can almost always find something other people created and start using them for your needs after simple installation steps. It accomplishes these tasks at the cost of performance - it is dynamically typed with an interpreter, garbage collected, and comes with a global interpreter lock (GIL for the dominant CPython at least). Many workarounds include interfacing with a lower-level language (C/C++) to get intrinsic speed and multithreading without the GIL. With enough care, you can usually get around the bottlenecks at hand and find new bottlenecks to be something else in a compute-centric system. Python is a T-shaped language.
Read more...
20 Dec 2022
I recently came across an article by Andrej Karpathy, ex-Sr. Director of AI at Tesla. Besides being impressed by the content, I was almost brought to tears. So much of it was what I personally experienced, learned the hard way, came to believe in, and decided to teach others. It felt vindicating to hear him say
…a “fast and furious” approach to training neural networks does not work and only leads to suffering… the qualities that in my experience correlate most strongly to success in deep learning are patience and attention to detail.
because I kept saying this but this point and its implications weren’t going through people’s minds.
Here I offer some of my own rules of training deep learning models. It might end up being a growing list.
Read more...
12 Oct 2022
This is a quick note on how to use openmp or rather, any multithreading library to divide the underlying data. Let’s use some code snippets from Faiss.
Usually you would parallel for, or first parallel then for over a sequence. For example:
int nt = std::min(omp_get_max_threads(), int(n));
#pragma omp parallel for if (nt > 1)
for (idx_t slice = 0; slice < nt; slice++) {
IndexIVFStats local_stats;
idx_t i0 = n * slice / nt;
idx_t i1 = n * (slice + 1) / nt;
I came across a different use case that was note-worthy:
Read more...
28 Sep 2022

For people who fool around in the small field of Approximate Nearest Neighbors (ANN) search, Faiss and hnswlib are two big names. Faiss is a much broader library with a lot of in-memory ANN methods, vector compression schemes, GPU counterparts, and utility functions, whereas hnswlib is a lot more specific, with only one graph-based in-memory index construction method called Hierarchical Navigable Small Worlds (HNSW) . After the open-source implementation of HNSW in hnswlib came out, Faiss also attempted it with its IndexHNSW class.
Which to pick? Being a long-time Faiss user, I had the natural inclination to keep using what it offered. However, issues ensued.
Read more...
27 Sep 2022
Not every business needs a Research function, certainly not every startup. However if a startup’s bread and butter is advanced technology, a sustained effort has to be put into maintaining it and cutting out new paths. The Research function’s role is to tease and trek into the unknown, to distill the craft into our potential area of expertise. In fulfilling this function, it needs to be comfortable not knowing how the piece of technology exactly fits into the product timeline and coordination - if we are confident in specing out even the big strokes at the beginning, it’s not research but engineering execution. Instead, it needs to do the following things.
- It needs to identify and appreciate a big challenge, take comfort and joy in the craft itself, and recognize the fact that the problem is meaningful enough that any findings coming out of it could shape key directions for the business.
- It needs to formulate hypotheses, set up environments to prove or disprove them quickly in the most representative yet still efficient way, and change course quickly in a matter of days and weeks. The code written and tools built during the many fail-fast attempts do not get thrown away, but factored into common elements and components in a broad collection of Swiss army knives that can be repurposed easily.
- It needs to be fixated on the important details, retain a long working memory, turn every stone and record them, and aim to incrementally become an expert on the subject.
- It needs to identify milestones particular to the different branching points, systematically approach them in overlapping time frames, and have the will to drive through to the conclusion.
Read more...
03 Sep 2022
You learned about this in college classes. You thought working SWE jobs in 2022 you’d never have to deal with this. But it comes back to trick you at your worst.
I was tripped by endian-ness when implementing inverted list listno-offset/LO as a fixed-width binary key in RocksDB.
// When offsets list id + offset are encoded in an uint64
// we call this LO = list-offset
inline uint64_t lo_build(uint64_t list_id, uint64_t offset) {
return list_id << 32 | offset;
}
inline uint64_t lo_listno(uint64_t lo) {
return lo >> 32;
}
inline uint64_t lo_offset(uint64_t lo) {
return lo & 0xffffffff;
}