The Wonders of RocksDB in Rust (Part III - MapReduce Group-By)
Feb 12, 2026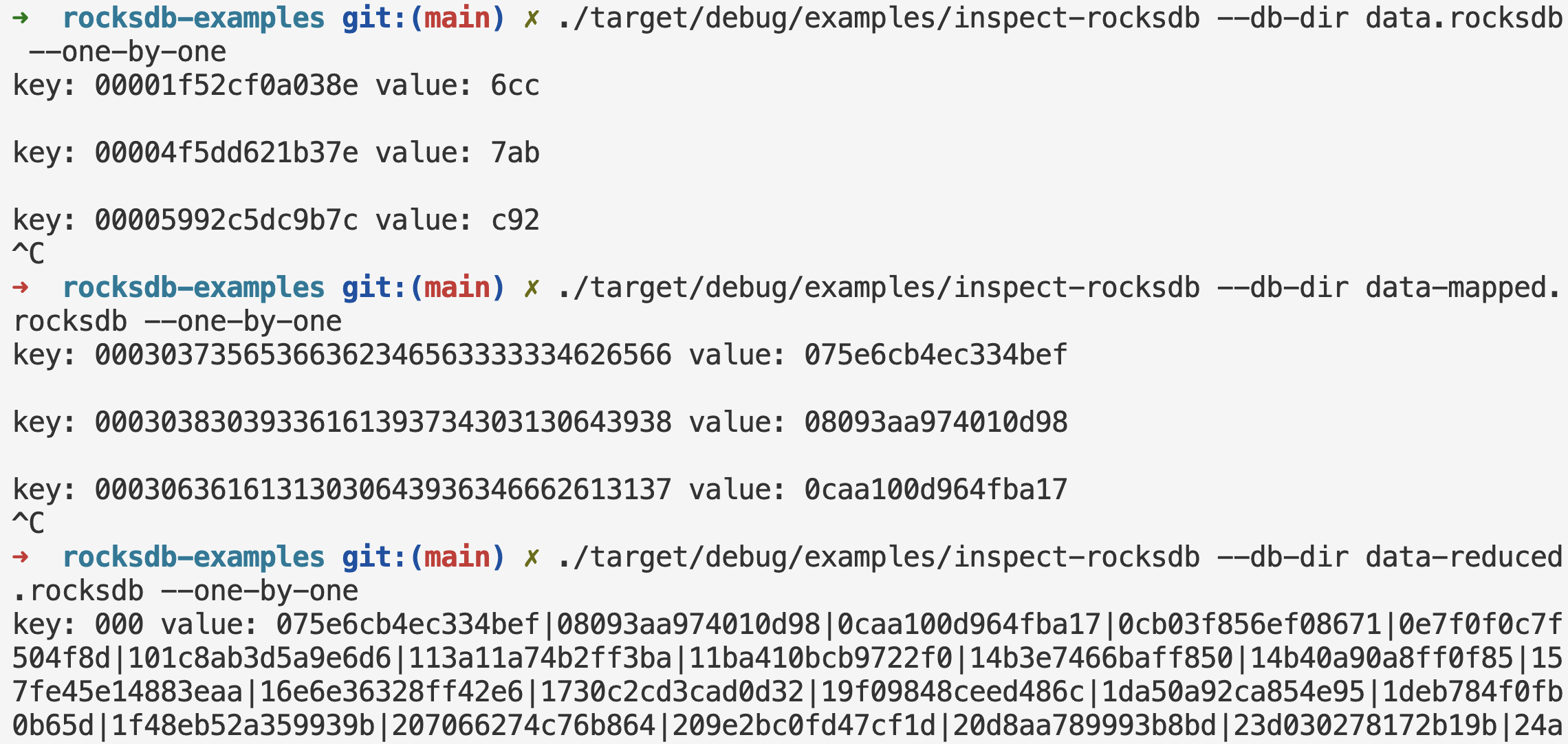
You can check out the code here.
This is the third and final part of the RocksDB in Rust series. In Part I, we looked at how to interact with RocksDB in Rust. In Part II, we looked at how to do parallel two-pointer set operations. In this part, we’ll look at how to do MapReduce for out-of-core aggregations.
Let’s look at the famed algorithm, MapReduce (Wikipedia). MapReduce is a programming model for processing large datasets in parallel originally targeting a big cluster of machines. It is a key component of the Hadoop ecosystem, and is still widely used today. MapReduce is a three-phase process:
- Map: The input is split into independent chunks, and each chunk is processed in parallel by a map function.
- Shuffle: The output of the map phase is shuffled and sorted by the grouping key.
- Reduce: The output of the shuffle phase is aggregated by a reduce function.
From the original paper abstract:
Our implementation of MapReduce runs on a large cluster of commodity machines and is highly scalable: a typical MapReduce computation processes many terabytes of data on thousands of machines.
Back in 2004, TBs of data on HDDs were considered large. In 2026, TBs of data can all fit on one machine with SSDs in RAID0. For example, on AWS EC2, you can get 120TB of NVMe drives on a single i7ie.48xlarge/i8ge.48xlarge instance. We can use one machine to run MapReduce to solve our Big Data problems.
Suppose we have a table with the primary key being hex strings simulating hashes. There is one other column that contains 3 hex characters. In practice, you can store anything into the value column with protobuf or other serialization formats. We want to aggregate the keys by the value, to turn this:
(5d46a9cbdcd7b1ee, 24f)
(41c35e778b34002b, 53a)
(554c67ebe57cbef2, 24f)
into this:
(24f, [5d46a9cbdcd7b1ee, 554c67ebe57cbef2])
(53a, [41c35e778b34002b])
For tabular data, this operation is also called group-by. DuckDB and Polars can do this, but they start to stress out beyond a certain size (several billions of entries), even with disk-spilling, because a lot of their query execution plans are in-memory. We can use RocksDB and Rust to do this, and it’s a lot more efficient without much memory usage at all.
See the full code.
Map Phase
We iterate through the database in parallel, and use the value with some unique identifier as the new key, and the original key as the new value to write into an intermediate database. One of the best ways to generate a unique identifier is to use the hex of the original key. Generating a hash from the key, or a random hash with sufficient bytes works, but there is a theoretical chance of collision.
We need a separator between the grouping key and the hex suffix. Using . is simple but has a pitfall: if one grouping key is a prefix of another, lexicographic order interleaves them. It is not the case for our specific example, because the values are simply 3 hex characters. However, real data may have all kinds of characters in the value. For example keys 24f[.0bc], 24f.A[.abc], 24f[.bbc] ([] only for illustration) sort correctly — so group 24f is split by 24f.A, and the Reduce phase (which assumes all entries for the same group are consecutive) will emit duplicate and incomplete groups, overwriting entries. To fix, we can use a reserved byte that cannot appear in the grouping key (e.g. \0). Then the grouping key sorts contiguously and you parse by splitting on that byte.
(key, value) -> (value + '\0' + hex(key), key)
let prefixes = generate_consecutive_hex_strings(3);
let pb = make_progress_bar(Some(prefixes.len() as u64));
let count = prefixes
.into_par_iter()
.map(|prefix| {
let prefix = prefix.as_bytes();
let mut db_iter =
db.full_iterator(IteratorMode::From(prefix, Direction::Forward));
let mut count = 0;
let mut write_batch = rust_rocksdb::WriteBatch::default();
while let Some(item) = db_iter.next() {
let (key, value) = item.unwrap();
if &key[..prefix.len()] != prefix {
break;
}
let key_hex = hex::encode(key.as_ref());
let new_key: Vec<u8> = value
.iter()
.chain(std::iter::once(&0u8))
.chain(key_hex.as_bytes())
.cloned()
.collect();
let new_value = key;
write_batch.put(&new_key, &new_value);
count += 1;
}
output_db.write_without_wal(&write_batch).unwrap();
pb.inc(1);
count
})
.reduce(|| 0_usize, |acc, c| acc + c);
output_db.flush()?;
pb.finish_with_message("done");
Shuffle Phase
Shuffle in RocksDB is done by simply running a full compaction after bulk loading. The sorted string table (SST) files are already sorted by the key, so the compaction will naturally shuffle the data by the new key.
let mut compaction_opts = rust_rocksdb::CompactOptions::default();
compaction_opts.set_exclusive_manual_compaction(true);
compaction_opts.set_change_level(true);
compaction_opts.set_target_level(ROCKSDB_NUM_LEVELS - 1);
compaction_opts
.set_bottommost_level_compaction(rust_rocksdb::BottommostLevelCompaction::ForceOptimized);
output_db.compact_range_opt(None::<&[u8]>, None::<&[u8]>, &compaction_opts);
Reduce Phase
We take the new key value + '\0' + hex(key), split on the first \0 to get the grouping key (original value), and group the original keys with ‘|’ to get the new value. This is a simple way to serialize the new value, and you can use any other serialization format you want.
(value + '\0' + hex(key), key) -> (value, key1|key2|...|keyN)
let prefixes = generate_consecutive_hex_strings(3);
let pb = make_progress_bar(Some(prefixes.len() as u64));
let counts = prefixes
.into_par_iter()
.map(|prefix| {
let prefix = prefix.as_bytes();
let mut db_iter =
db.full_iterator(IteratorMode::From(prefix, Direction::Forward));
let mut write_batch = rust_rocksdb::WriteBatch::default();
let mut count = 0;
let mut count_grouped = 0;
let mut prev_key = Vec::<u8>::new();
let mut blobs_vec: Vec<Vec<u8>> = vec![];
while let Some(item) = db_iter.next() {
let (key, value) = item.unwrap();
if &key[..prefix.len()] != prefix {
break;
}
// key is value + '\0' + key_hex; group by value = everything before first '\0'
let sep = key.iter().position(|&b| b == 0).unwrap_or_else(|| {
panic!("Invalid key: {}", String::from_utf8_lossy(&key))
});
let new_key = key[..sep].to_vec();
if new_key != prev_key {
if !prev_key.is_empty() {
// concatenate with '|'
// can use protobuf or anything else to serialize
let new_value: Vec<u8> = blobs_vec.join(&b"|"[..]);
write_batch.put(prev_key, new_value);
count_grouped += 1;
}
blobs_vec = vec![];
prev_key = new_key;
}
blobs_vec.push(value.to_vec());
count += 1;
}
if !blobs_vec.is_empty() {
let new_value: Vec<u8> = blobs_vec.join(&b"|"[..]);
write_batch.put(prev_key, new_value);
count_grouped += 1;
}
output_db.write_without_wal(&write_batch).unwrap();
pb.inc(1);
(count, count_grouped)
})
.reduce(
|| (0_usize, 0_usize),
|accs, counts| (accs.0 + counts.0, accs.1 + counts.1),
);
output_db.flush()?;
pb.finish_with_message("done");
Then you get the final results shown in the image at the beginning of this post.